


Machine Learning Classifications: An Overview
A Comprehensive Guide to Different Types of Machine Learning


ML is divided into four parts. They are :
Supervised Learning
Unsupervised Learning
Semi-Supervised Learning
Reinforcement Learning
Supervised Learning is subdivided internally.
Regression
Classification
Unsupervised is also subdivided internally.
Clustering
Dimensionality Reduction
Anomaly Detection
Association Rule Learning

Supervised Learning
If data has both input and output and training a model is a way to find out the relation between them and predict the unseen data, it is called Supervised Learning.
Example
IQ CGPA PLACEMENT (Y/N) 80 7.5 N 90 8 Y 111 7.9 Y 70 6 N we have the above data of 5000 rows. we can easily say that "IQ" and "CGPA" are inputs and "PLACEMENT" is the output in the above table. In the above data, we have both input as well as output. The work of any ML algorithm is to draw a mathematical relationship between inputs and output. Now the ML algorithm can predict unseen data {100,9} with the help of the drawn relation. This is called Supervised Machine Learning.
Supervised ML has two parts Regression and Classification.
Before we go any further we need to know the two data types. The first is Numerical (ex: 1, 5 ). The second is Categorical. Categorical data is a type of data, that is used to group information of similar characteristics.
Regression
If you are applying a Supervised ML Algorithm to a dataset. If that dataset has a numerical output then that Supervised ML Algorithm applied on the dataset is called Regression.
Example:
IQ CGPA PACKAGE(LPA) 80 7.5 8 90 8 10 111 7.9 15 70 6 7.5 Here in the above dataset, the inputs are IQ and CGPA, and the output is PACKAGE. So, the Supervised ML Algorithm applied to the above dataset is called Regression.
Classification
On the contrary, if the output is Categorical then the Supervised ML Algorithm used is called Classification.
Example
IQ CGPA PLACEMENT (Y/N) 80 7.5 N 90 8 Y 111 7.9 Y 70 6 N Here in the above dataset, the inputs are IQ and CGPA, and the output is PLACEMENT. So, the Supervised ML Algorithm applied to the above dataset is called Classification.
Unsupervised Learning
Differing from supervised, the dataset for unsupervised has only inputs and no output. The ML algorithm used for this dataset cannot predict tasks. Instead, it can do the following:
Clustering
Dimensionality Reduction
Anomaly Detection
Association Rule Learning
Clustering
Grouping data points with similar characteristics into separate groups is called Clustering. Let's understand it with an example.
Example:
In the figure above, if we look at the plot on the left, we can see that three groups can be formed. The clustering algorithm identifies the number of groups and creates a clustering region for each group.

Dimensionality Reduction
Dimensionality Reduction is a powerful technique. When you apply a Supervised ML Algorithm to a dataset, it may have thousands of input columns. Having so many input columns can slow down the ML algorithm because it has to process a large amount of data. After a certain point, adding more input columns doesn't improve the prediction. Dimensionality Reduction decreases the number of input columns. It is also useful when your data has many dimensions that can't be visualized by plotting. Dimensionality Reduction can reduce these to 3 dimensions, making them easier to visualize.
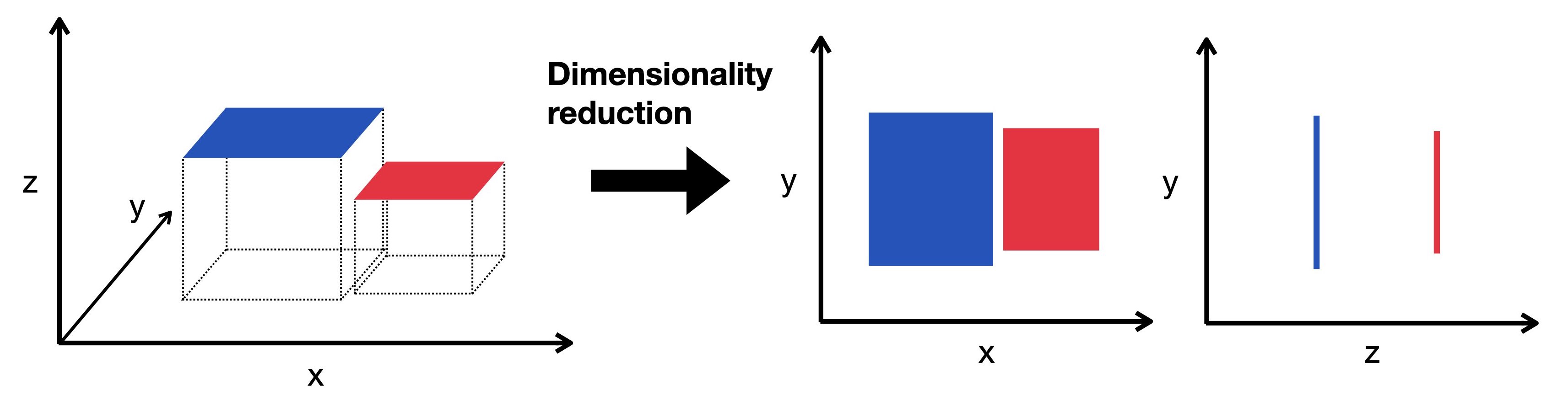
Anomaly Detection
It is a technique used to identify certain pieces of data that differ from the majority of data and don't fit the normal behavioral pattern. It is also called Outlier Detection.

Association Rule Learning
It is a detective in the data world. It finds surprising connections between things people buy, websites they visit, or the articles they read.

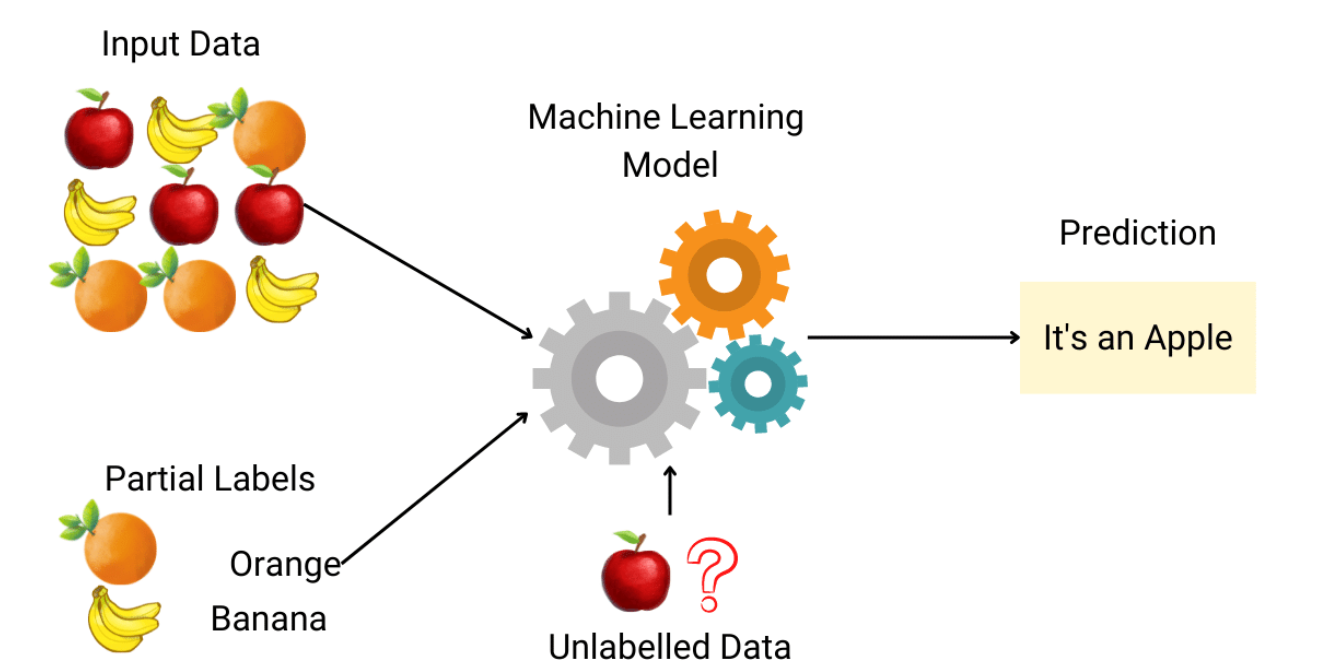
Semi-Supervised Learning
Now, from the name itself, you must have understood it is partially supervised and partially unsupervised. Creating labels for a dataset is called Labeling. It is a costly task because it requires manual work. The core idea behind semi-supervised learning is to label a small amount of data and then let the system automatically label the rest.
Reinforcement Learning
Think of it as training a dog with rewards. An AI learns by trying actions and getting "treats" for good choices.

Conclusion
In conclusion, machine learning is divided into various methodologies tailored to different types of data and objectives. Supervised learning, with its regression and classification techniques, is ideal for datasets with clear input-output relationships. Unsupervised learning excels in discovering hidden patterns through clustering, dimensionality reduction, anomaly detection, and association rule learning. Semi-supervised learning strikes a balance by leveraging both labeled and unlabeled data, while reinforcement learning mimics the process of learning through rewards and penalties. Understanding these classifications and their applications is crucial for effectively leveraging machine learning to solve complex problems.